
Context
Typically, predictive modeling is realized as one step in a multi-step process of a data mining workflow. An industry standard for such a process is CRISP-DM (cross-industry standard process for data mining). This process was defined in 1996 and is applicable in a big data environment as well. It is still state of the art, and the below picture illustrates typical steps in this process, where (predictive) modeling is one of these:
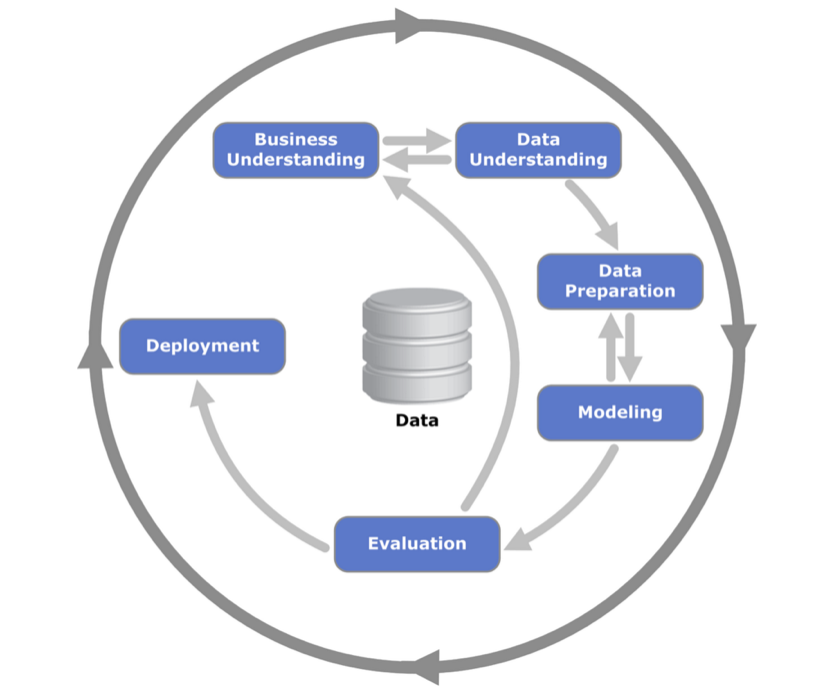
In addition to the steps illustrated in this picture, you can add sub-steps, such as feature engineering, feature selection, or sampling. Datameer can be used to address each of these. In this article, we focus on the modeling aspect and explain how Datameer can be used in that context.
Predictive vs. Descriptive
In descriptive data mining the goal is to understand the data and discover patterns. In Datameer this goal can be achieved through manual workbook functions (such as simple group-by or group-count) as well as through Smart Analytics components. For example, the decision tree can reveal how a number of input features determine the values of a target feature.
In predictive data mining the approach is to have an algorithm learn a model on training data and then apply that model to new data (where the values of the target feature are unknown) to make predictions. Typical algorithms in that area are Logistic Regression, Random Forrest or Deep Learning. Today, such algorithms don't come out-of-the-box with Datameer. However, Datameer can be integrated in the CRISP-DM process to cover the modeling step for predictive models. This particular modeling step is done outside of Datameer and the resulting model can be imported back into Datameer for the prediction or scoring step.
Inside vs. Outside of Datameer
Depending on the algorithm it could be a good choice to integrate with a third party tool and to leave Datameer for the modeling step. In other situations it can make sense to implement the modeling step within Datameer. The following picture illustrates the main aspects to consider when deciding which approach to use:
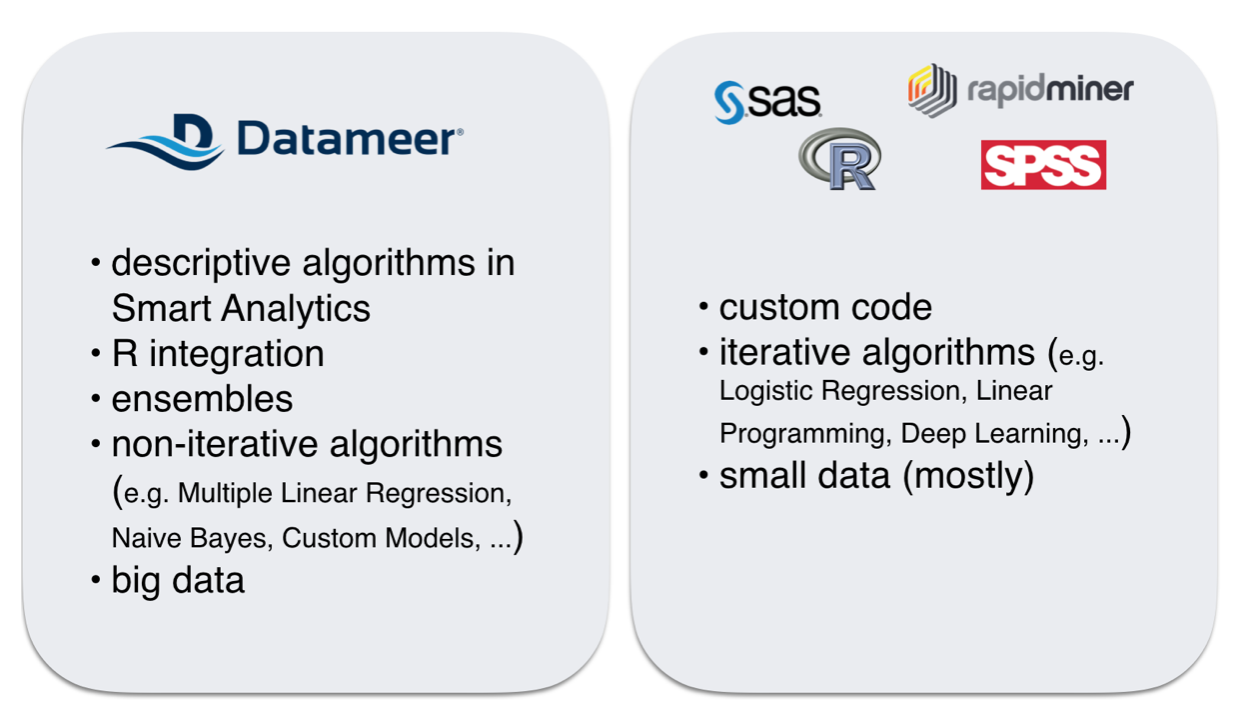
As previously mentioned, the Smart Analytics component comes with some descriptive algorithms out-of-the-box, which can help with data discovery.
Another option is to integrate Datameer with R. In this case the Datameer SDK is utilized to write a custom function that passes the data to R and executes some R code on it. The resulting model can be passed back into the Datameer spreadsheet to be applied on new data to make predictions.
This can also be integrated with an ensemble approach. Because R can only deal with data that fits into memory (on one single node), it might be necessary to split up the data into a number of smaller subsets. The R integration would then train one model per subset and then combine these models in the prediction/scoring step in Datameer as an ensemble.
Generally, the Datameer SDK can be used to implement custom functions. For predictive modeling, such custom functions can address any algorithms that are not iterative, because the SDK's abstraction layer on top of Map/Reduce allows for one map or one map-reduce step per custom function. Thus, iterative algorithms aren't practical to implement using the Datameer SDK. Examples of not iterative algorithms are Multiple Linear Regression or Naive Bayes.
For iterative algorithms the approach is to set up an export job in Datameer to export a sample of the data that can be used in an external tool for the modeling step. Such tools often support to export a model into the PMML format, which can then be used to import it back into Datameer for the prediction/scoring step.
In general, big data modeling should be done within Datameer, and small data modeling can be done outside of Datameer.
Big Data vs. Small Data
If an iterative algorithm needs to be used for modeling, a sample of small data has to be drawn to use that sample in a tool outside of Datameer. The below picture illustrates how the CRISP-DM workflow is affected in such a situation:
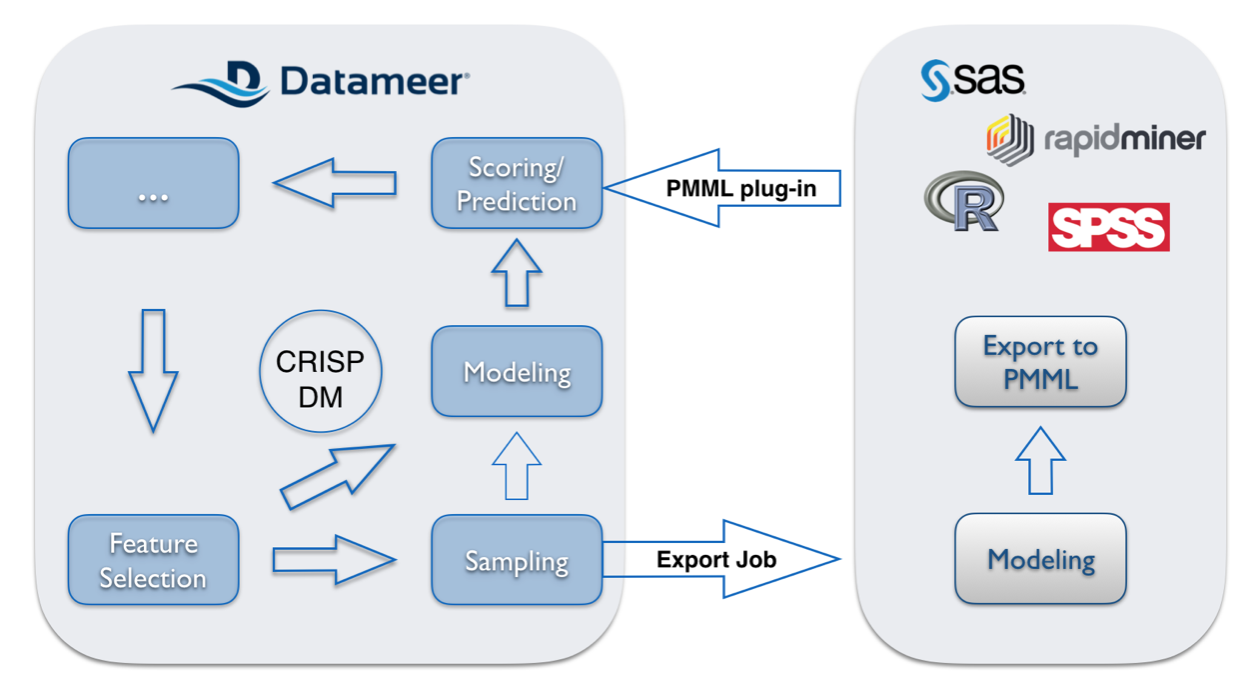
Datameer can be used to draw a sample (several workbook functions support such a use case). An export job can write that sample to a location outside of Datameer. A third party tool can then be used to train a model on that data and to export that model to PMML. Finally, the Datameer PMML plug-in import such a model and continue with the scoring/prediction step on big data inside Datameer.
Comments
0 comments
Please sign in to leave a comment.