Clustering results don't converge

Hi,
for data from production lines I am applying the clustering feature of smart analytics. I tried with different numbers of clusters. Normally I would expect less cost (sum of square of distance from centroid) for higher number of clusters. This could be observed in some cases but not always. In the following case it looks good. The cost decreases with more clusters. I also calculated the silhouette index which grows near to 0.9. Here I get good clusterings.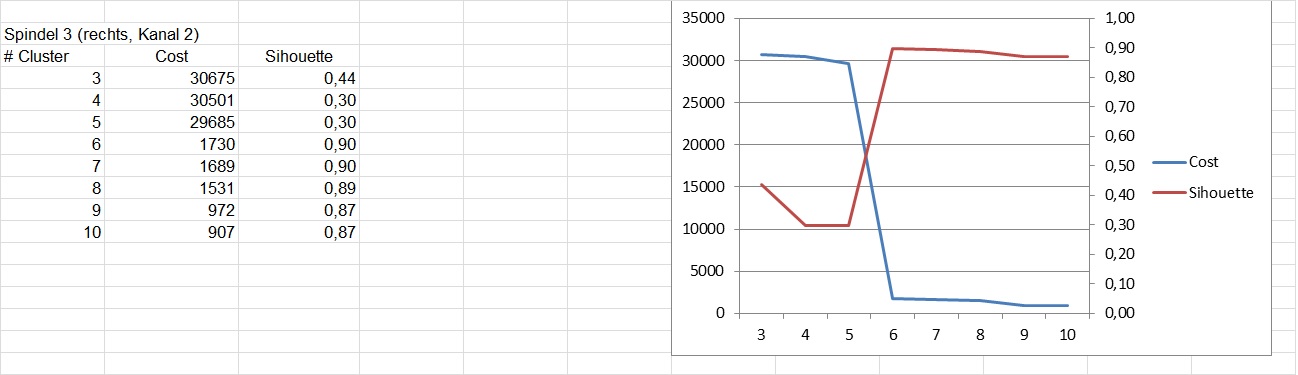
In this cases it works not well. Clustering multiple times even with same number of clusters I get sometimes very different results:
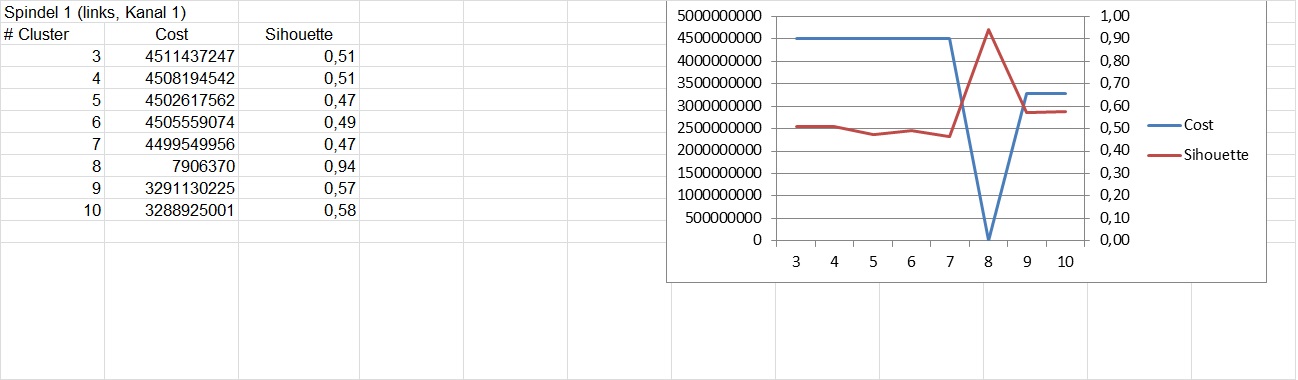 The low cost value and high silhouette with 8 clusters could be produced with multiple attempts. I always reported the best value, 8 clusters also produced 4 billion sometimes. But with 9 and 10 clusters I could never get a good value.
The low cost value and high silhouette with 8 clusters could be produced with multiple attempts. I always reported the best value, 8 clusters also produced 4 billion sometimes. But with 9 and 10 clusters I could never get a good value.
I know, that k-means very much depends on initial values. That is why k-means ++ cares about it. Therefor I am a little surprised. Best cost for 8 clusters is below 8 million. If you use k-means ++ the expectation of costs is not bigger than 8*(ln k +2) times of the optimum. In my case the factor is about 34 but the figures flip by a factor of 400. And for 9 and 10 clusters I could not produce good results with many attempts.
My questions. Do you use k-means ++ internally? Do you have an explanation? Do you have any hint to improve it. The case could become very valuable for manufactureres if it works.
-

Fritz, thank you for the question. As documented in our Clustering page, Datameer uses the standard k-means algorithm, not the k-means++ algorithm. As you highlighted, the standard k-means algorithm does have limitations when selecting initial cluster centers -- this could be the root cause of this particular data sample's inconsistency with cluster results.
It may be possible to create a k-means++ style algorithm using our SDK. Alternatively, our Professional Services team could scope building a solution using the k-means++ updated algorithm.
-
Hi Joel, thanks for the answer. Sorry to hear, that Datameer does not use k-means++. Since with Mahout and SparkML there are two k-means-implementation on Hadoop doing the improved initiatization, I thought Datameer would leverage one of them and does the same. Do you see a chance to add a k-means option in one of the next releases? We could connect SparkML k-means++ via SDK like we did with other machine learning algorithms, but it is hard to argue Datameer value-add then.
-
Thank you for the update Fritz. I've created an enhancement request, which is known internally as DAP-34471 on your behalf.
Please note that enhancement requests are evaluated and considered by the Datameer Product Management team. Not all enhancements will be implemented into a future Datameer release. If an enhancement request is selected by Datameer Product Management to be implemented in a future release, an estimated release date or version may not be available.
Please sign in to leave a comment.
Comments
3 comments