
Goal
Typically when data is imported from large tables a full replace is not feasible from a timing/performance perspective, the next best approach is to perform incremental updates/appends. This article shows one way to handle this cases using append imports and workbook de-duplication.
Learn
Prerequisites
- The source table needs a field or column with an updated time stamp that identifies records recently inserted or updated. This time stamp is common in RDBMS data models.
- The table should have an index on the time stamp field or column to ensure optimal performance when the Datameer or Hadoop job queries the database and filters on this field to identify new and updated records.
Steps
- Define an import job from the source table, using the update_dt field as the split column so you can leverage it when selecting the append option. This action ensures that only new and updated records are picked by the next scheduled job and appended into the existing import artifact, rather than re-ingesting the whole table.
- Create a new workbook from the import job. This workbook is necessary because when records are appended, updates appear as duplicates, because there are no drop or delete options in Hadoop without incurring a heavy process. Therefore, a workbook with a de-duplication logic needs to be defined.
- Create a new sheet (de-dup sheet) and use a GROUPBY() function on the fields that uniquely identify each record, or the primary keys of the source table.
- Use the GROUPTOPN() function on the update_dt key column with N set to 1. This function sorts and picks the latest update+dt record.
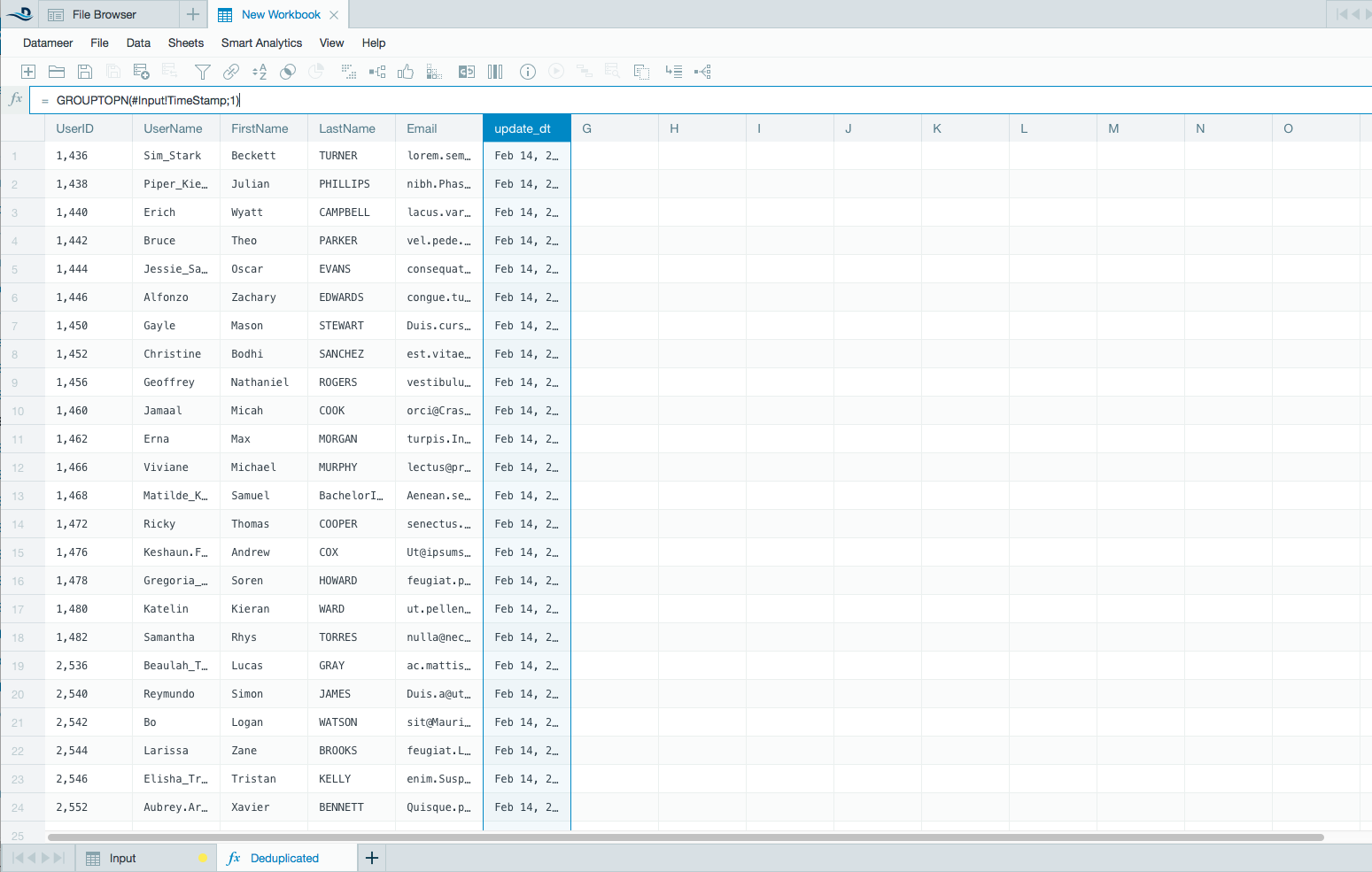
- Use the COPY() function for the rest of the columns. The GROUPTOPN function makes sure only the last record is selected. Note: When working with tables with multiple columns, Datameer recommends using the REST API to automate the process of defining the de-duplication sheet.
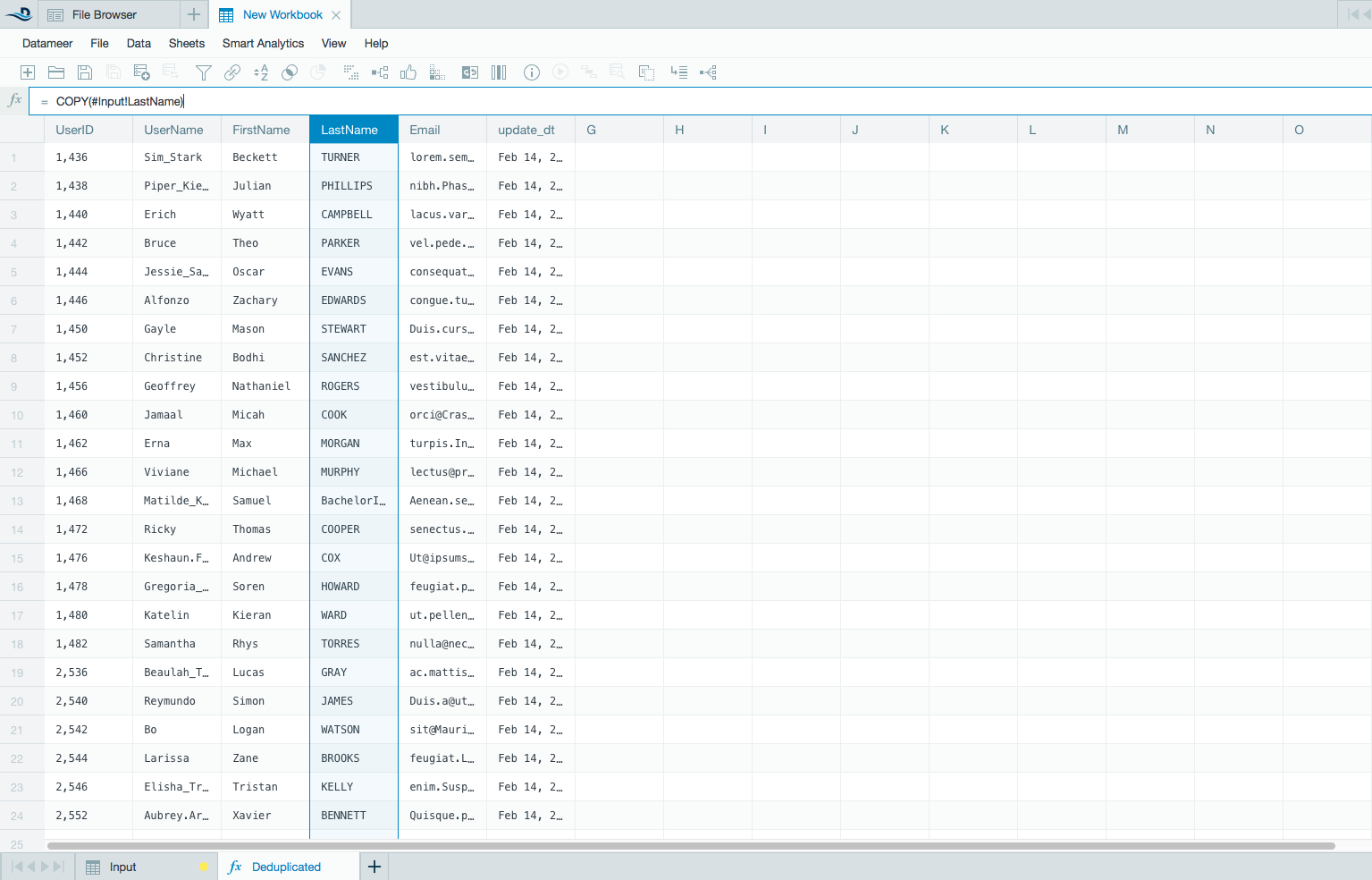
- Save the workbook and keep only the de-dup sheet.
- Downstream analysis can use the de-dup sheet as a source that only contains the latest record. Otherwise, users can use the import and define de-duplication on their workbooks.
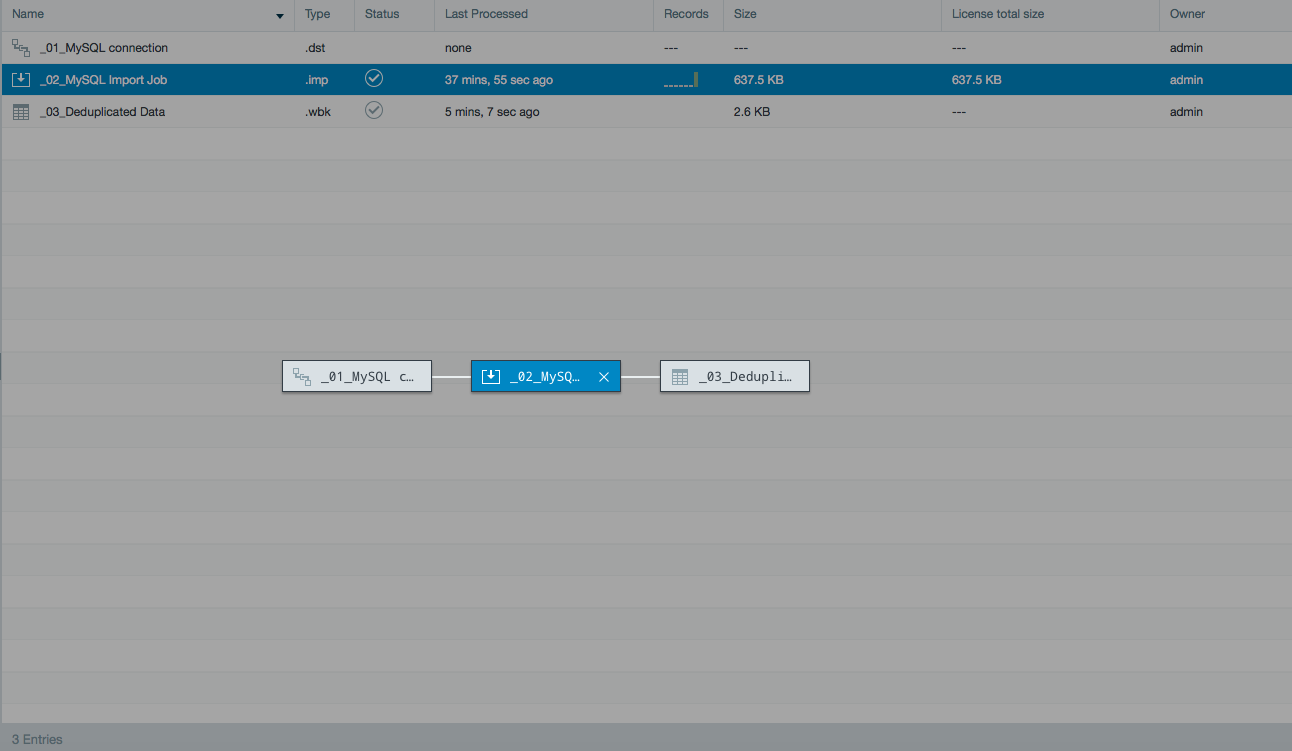
This is how the data lineage should appear:
Tips
When the de-duplication workbook is processed, de-duplication occurs on the entire dataset. To improve performance, Datameer recommends using partitions on the import so only the necessary partitions for the analysis are used.
Comments
0 comments
Article is closed for comments.