
Goal
I want to collect the YARN application logs.
Learn
There are times when the Datameer job trace logs might not provide enough information for effective troubleshooting of an issue. When this happens, you may be asked to provide the YARN application logs from the Hadoop cluster.
To do this, you must first discern the application_id of the job in question. This can be found from the logs section of the Job History for that particular job id. First you must navigate to the job run details for the job id # in question:

Once there, scroll to the bottom to the Job Log section and look for the line Submitted Application <application_id>:
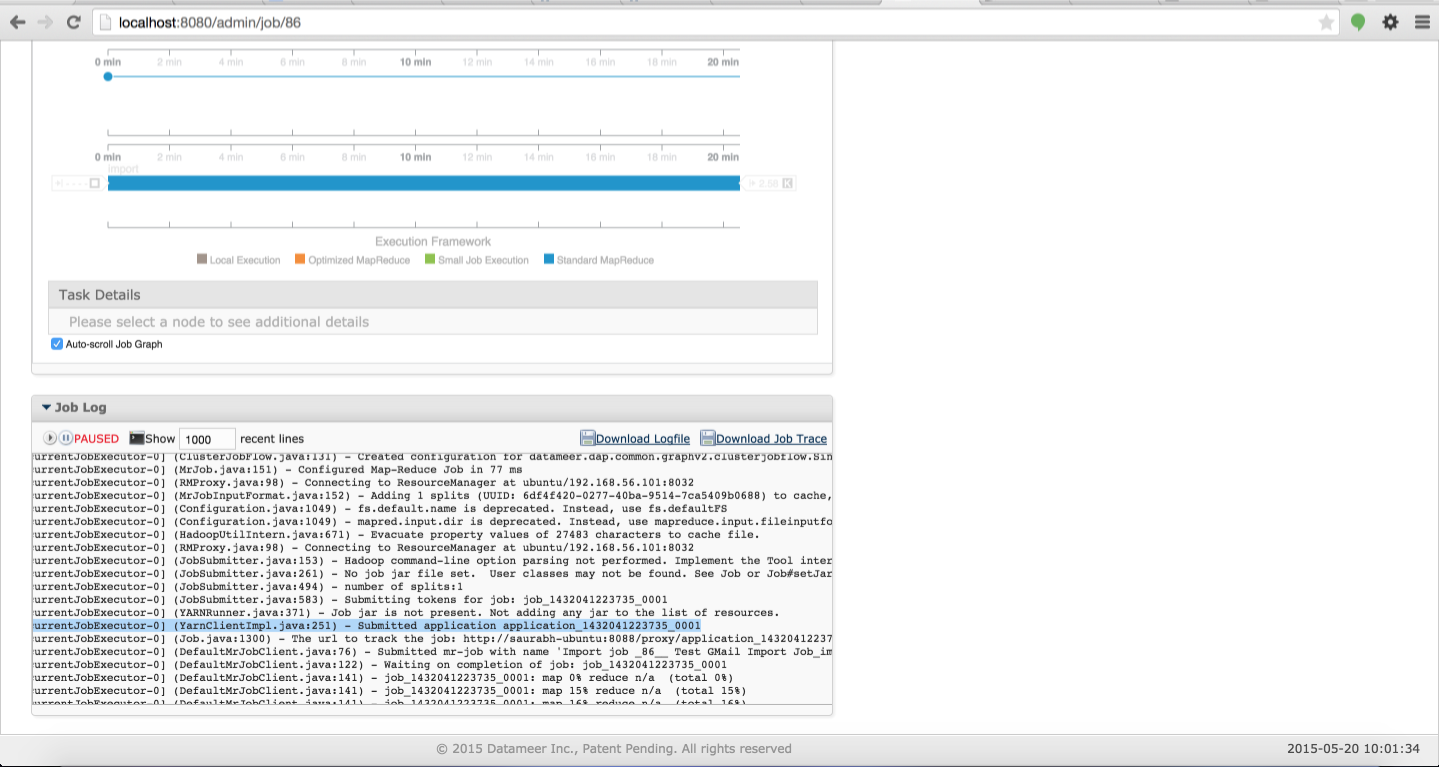
Once the application_id is obtained, you can execute the following command from the command line on the Resource Manager to obtain the application logs:
yarn logs -applicationId <application_id>
Continuing with the above example, the following command would be executed:
yarn logs -applicationId application_1432041223735_0001 > appID_1432041223735_0001.log
Please note that using the `yarn logs -applicationId <application_id>` method is preferred but it does require log aggregation to be enabled first. If log aggregation is not enabled, the following steps may be followed to manually collect the YARN Application logs: How to Collect the YARN Application Logs - Manual Method
Comments
1 comment
While likely known, may want to include the pipe redirection as part of the example on how to save the log so that it can be sent over to DataMeer Support if it becomes an issue.
Please sign in to leave a comment.