
Goal
In this workbook guide, you will learn how to optimize a workbook when you save and configure it.
Note
For this tutorial, you may need admin privileges. If you’re not an admin on your production instance, you can download a personal trial and explore many administrative options.
Sample data
Download the Tutorial Click Path app from the Datameer App Market to follow along with the example.
Learn
Configure your workbook
After downloading and running the Tutorial Click Path app, click on the Browser tab at the top of the screen.
Open the folder for the Click Path Analysis app and right-click on the workbook file. Select Configure.
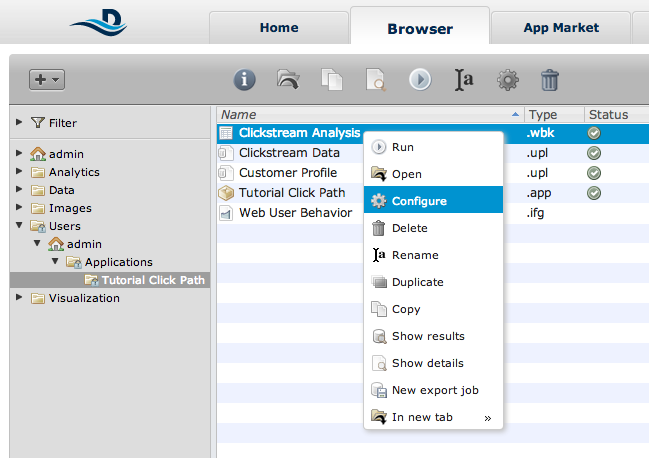
From here, you can configure all the settings of the workbook.
Setting the data retention and which sheets need their full data saved
Look for the section named Data Retention. This section has settings that lets you determine how many workbook runs will be saved.
This refers to the full data sets that are being created every time you run your workbook. By default, Datameer saves only the last run, as shown in this configuration:
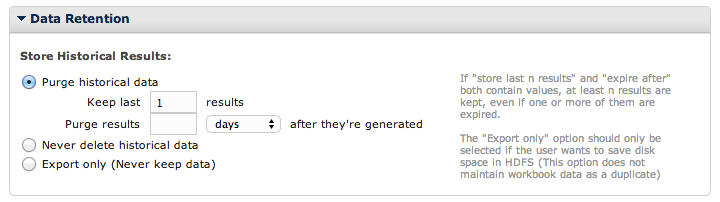
This setting is the best data retention policy for a workbook to create the most efficient workbook.
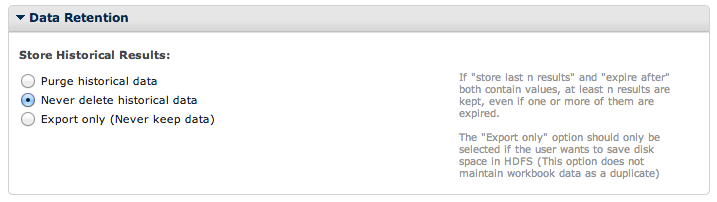
You may select to never purge data, which will save ALL runs. This would allow you to compare old runs, but take into consideration that it does take up extra storage space.
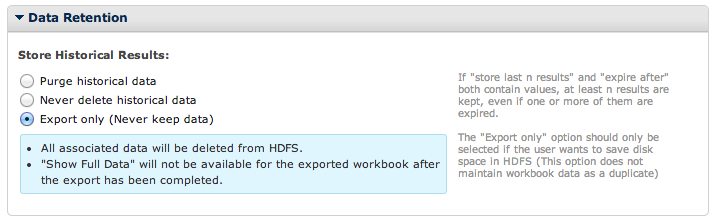
If you choose Export Only, you need to create an export job in order to save this data. This data will be cleaned up in HDFS as soon as the export is completed, or in 24 hours (whichever comes first).
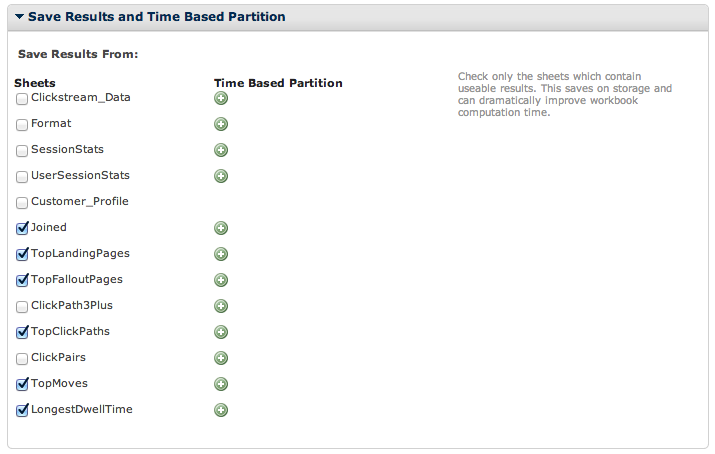
Next, navigate to the Save Results and Time Based Partition section. Only check the boxes for the sheets in which you need to save. If there is a check next to a sheet, this means that the full data will be saved for that sheet.
By not saving all the sheets, you will save storage space and decrease the time it takes to run a workbook as less data is being saved and processed. You can determine which sheets should be saved by asking yourself “will this sheet be used for infographics or for reporting?”. If your sheets will NOT be used outside of the workbook, don’t save them! By looking at the image below, you will see that the saved sheets correspond with the infographics for this app.
Choose custom Hadoop properties
Now, move down to the Advanced section in your workbook configuration. Here, you will see a form for Custom Hadoop Properties. This allows you to configure properties on how the job will run. For example, you can set properties such as how many other jobs can run at the same time as this one. This would allow you to minimize the traffic on the machine and allow the job to run faster. This configuration would look like this:
das.job.concurrent-mr-job=<numerical value>
In this example, the concurrent jobs to be run while this job is running has been set to 6.
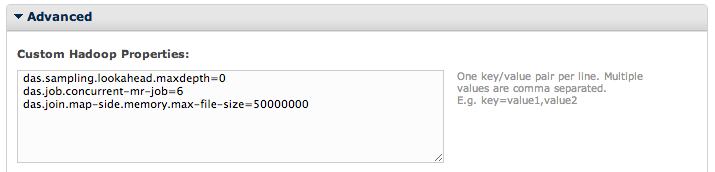
Additionally, a property to turn off sampling has been added:
das.sampling.lookahead.maxdepth=<numerical value>
This property disables Smart Sampling and is based on a random sample.
Also, you will see that you are able to allocate more memory to this job with the following property:
das.join.map-side.memory.max-file-size=<numerical value>
This property allows the workbook to use more memory than other jobs on the machine. The numerical value entered is in bytes.
Select the compression
In the same Custom Hadoop Properties field, you can also select your compression type for the workbook. Here, you can choose the compression that will best optimize your workbook.
What is the best compression, you ask? Well, that depends on your workbook! For example, if your workbook takes a toll on your CPU, you may want to choose Snappy compression because it focuses on speed, not maximum compression.
Once you select your compression type, you will add this configuration to the field.
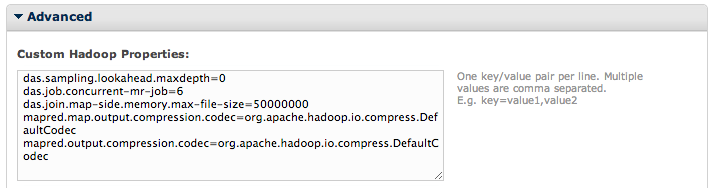
In this case, we have added the default just to give you an idea of what this looks like:
# Defines the compression codec of the output of Map
mapred.map.output.compression.codec=org.apache.hadoop.io.compress.DefaultCodec
# Defines the compression codec for the final output of a Map-Reduce job
mapred.output.compression.codec=org.apache.hadoop.io.compress.DefaultCodec
You can find the different compression configurations in our Frequenly Asked Questions.
Now you are finished with your job optimization.
Comments
0 comments
Please sign in to leave a comment.